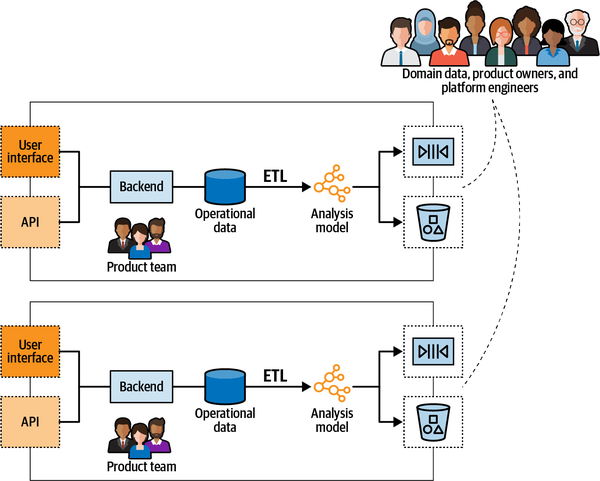
The data mesh architecture defines and protects model and ownership boundaries for analytical data.
At its core, it applies the same principles as domain-driven design but to analytical data: decomposing the analytical model into manageable units and ensuring that the analytical data can be reliably accessed and used through its public interfaces.
Why
Data mesh addresses some limitations of data warehouse and data lake architecture when the coupling to the implementation models of the operational system, or domain knowledge gap between operational and analytical teams slows down progress, creates friction between R&D and data teams.
Four core principles
Decompose data around domains
Instead of building a monolithic analytical model, use multiple models and align them with the origin of the data.
Each bounded context should own its operational and analytical models. It means the same team is responsible for transforming operational to analytical models when changes are required.
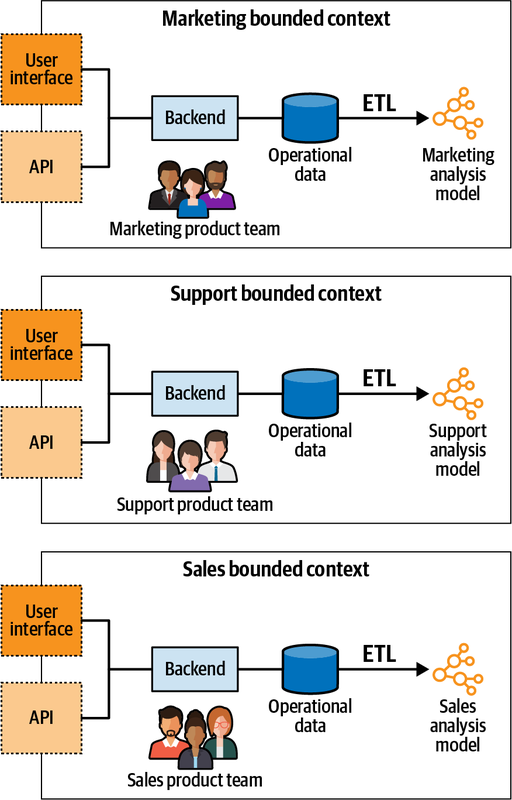
This way the domain knowledge, ubiquitous language are preserved and reflected in both operational and analytical models.
The published analytical model that is different from operational model is the open-host pattern (the analytical model is an additional published language in this case).
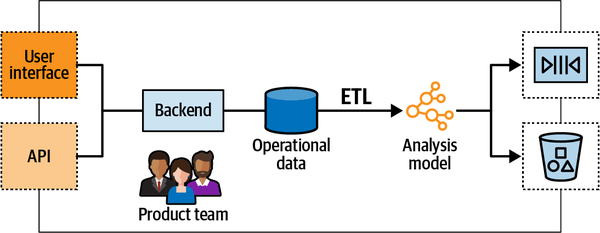
Data as a product
Instead of the analytical system having to get the operational data from dubious sources (internal database, logfiles etc.), in a data mesh–based system the bounded contexts serve the analytical data through well-defined output ports.
Analytical data should be treated as a first-class citizen, like any public API:
- It should be easy to discover the necessary endpoints: the data output ports.
- The analytical endpoints should have a well-defined schema describing the served data and its format.
- The analytical data should be trustworthy, and as with any API, it should have defined and monitored service-level agreements.
- The analytical model should be versioned as a regular API and manage integration-breaking changes in the model.
Analytical data should address the needs of its customers. Data quality is a top-level concern.
Data products have to be polyglot, serving the data in formats that suit different consumers’ needs (SQL queries, object storage service etc.).
Each product team require additional data-oriented specialist.
Enable autonomy
The product teams should be able to both create their own data products and consume data products served by other bounded contexts.
Data products should be interoperable.
Build an ecosystem
A federated governance group should be appointed to the data mesh system.
The group may consist of the bounded contexts’ data and product owners and representative of the data infrastructure platform team.
The group is in charge of defining the rules to ensure a healthy and interoperable ecosystem. The rules have to be applied to all data products and their interfaces. It’s the group’s responsibility to ensure that rules are adhered throughout the organization.