q Can I stop a Redshift instance, when I’m not using it?
Fully managed, petabyte-scale data warehouse service in the cloud.
AI powered, massively parallel processing (MPP) architecture
- No code/low code zero-ETL approach possible.
- Built-in ML with AWS SageMaker.
- Massively parallel processing (MPP) architecture.
- Near real-time analytics.
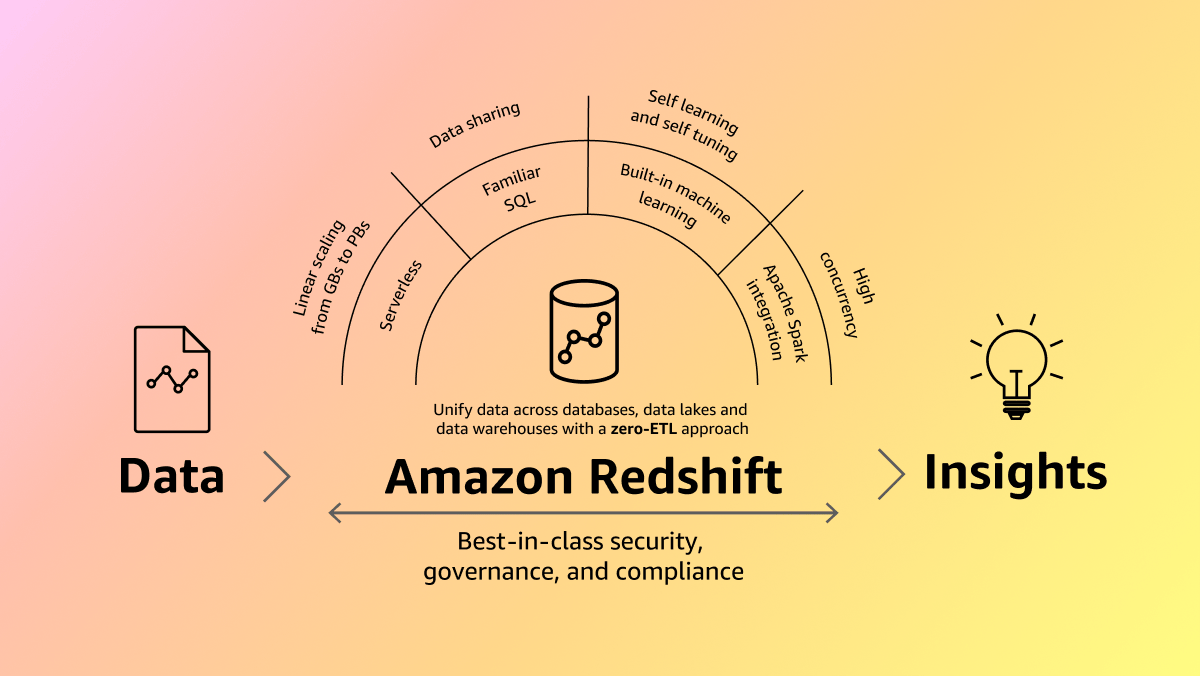
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes.
As far, as I understand, there are 2 versions of Redshift:
- Redshift
- Redshift Serverless
And AWS are pushing Serverless option more. But I think I need to focus on the non-Serverless option first, as it probably will be used in the production on Spark.
Data can be queried from the Redshift database, as well as outside of it:
- S3 files in many formats, including Parquet, ORC, RCFile, TextFile, SequenceFile, RegexSerde, OpenCSV, and AVRO.
To define the structure of the files in Amazon S3, you create external schemas and tables. Then, you use an external data catalog such as AWS Glue or your own Apache Hive metastore.
After your data is registered with an AWS Glue Data Catalog and enabled with AWS Lake Formation, you can query it by using Redshift Spectrum.
Terminology
- Namespace is a collection of database objects and users. Data properties include database name and password, permissions, and encryption and security.
- Workgroup is a collection of compute resources from which an endpoint is created. Compute properties include network and security settings.
Import data from S3 CSV
Docs The fastest way to import a big dataset.
path = f"s3://{s3_bucket}/{s3_key}"
statement = f"""
COPY {self.root_db_name}.{db_name}_{NEW_DB_SUFFIX}.{table_name}
FROM '{path}'
IAM_ROLE '{role_arn}'
FORMAT CSV
IGNOREHEADER 1
DELIMITER ';'
COMPUPDATE OFF
DATEFORMAT 'auto'
NULL AS 'null'
;"""
conn.execute(sa.text(statement))