Example of the Terraform code to configure auto scaling for the ECS service (Fargate-based).
Worth noticing:
lifecycledirective foraws_ecs_serviceto ignore changes to the propertydesired_count(targeted to auto scale), so thatterraform applywould not interfere with the auto scaling.- To scale to zero separate metric is used, because the “direction” of comparison matters: for
GreaterThanOrEqualToThresholdoperator or similar we can “listen” to only positive values above the threshold and vice versa. The second alarm mentioned here, and it nudged me in the right direction. Because initially I’ve tried to use a second alarm that listens for0in the SQS queue depth, as well as trying to fit everything into one alarm, using negative lower/upper bounds in auto scaling policies that did work to scale out, but not for scaling in. step_adjustmentinline blocks are generated using some factor (1.25for example) and gradually increasing the next threshold to spin more containers. Nothing complex, did it as an alternative to a cumbersome manual input. In the end the scaling policy looks like this:
resource "aws_ecs_cluster" "main" {
name = "${local.name_prefix}-cluster"
}
resource "aws_ecs_service" "scanner" {
name = "scanner"
cluster = aws_ecs_cluster.main.id
task_definition = aws_ecs_task_definition.scanner.arn
desired_count = 0
launch_type = "FARGATE"
network_configuration {
subnets = [aws_subnet.private1.id]
security_groups = [aws_security_group.scanner.id]
}
lifecycle {
ignore_changes = [desired_count]
}
}
resource "aws_appautoscaling_target" "scanner_service" {
min_capacity = 0
max_capacity = var.max_scanners
resource_id = "service/${aws_ecs_cluster.main.name}/${aws_ecs_service.scanner.name}"
scalable_dimension = "ecs:service:DesiredCount"
service_namespace = "ecs"
}
resource "aws_appautoscaling_policy" "scale_out_scanner_based_on_queue_depth" {
name = "scale-out"
policy_type = "StepScaling"
resource_id = aws_appautoscaling_target.scanner_service.resource_id
scalable_dimension = aws_appautoscaling_target.scanner_service.scalable_dimension
service_namespace = aws_appautoscaling_target.scanner_service.service_namespace
step_scaling_policy_configuration {
adjustment_type = "ExactCapacity"
cooldown = 60
metric_aggregation_type = "Average"
dynamic "step_adjustment" {
for_each = range(1, var.max_scanners + 1)
iterator = step
content {
metric_interval_lower_bound = floor((step.value - 1) * var.trigger_messages_threshold * pow(var.scanner_scaling_factor, step.value - 1))
metric_interval_upper_bound = step.value == var.max_scanners ? null : floor(step.value * var.trigger_messages_threshold * pow(var.scanner_scaling_factor, step.value))
scaling_adjustment = step.value
}
}
}
}
resource "aws_appautoscaling_policy" "scale_in_scanner_to_zero" {
name = "scale-in"
policy_type = "StepScaling"
resource_id = aws_appautoscaling_target.scanner_service.resource_id
scalable_dimension = aws_appautoscaling_target.scanner_service.scalable_dimension
service_namespace = aws_appautoscaling_target.scanner_service.service_namespace
step_scaling_policy_configuration {
adjustment_type = "ExactCapacity"
cooldown = 60
metric_aggregation_type = "Average"
# When below the threshold, scale in to zero
step_adjustment {
metric_interval_upper_bound = 0
scaling_adjustment = 0
}
}
}
# CloudWatch Alarm for the SQS queue to monitor the number of messages in the queue
resource "aws_cloudwatch_metric_alarm" "uploads_queue_depth_above_threshold" {
alarm_name = "${local.name_prefix}-queue-depth-above-threshold"
comparison_operator = "GreaterThanOrEqualToThreshold"
evaluation_periods = 1
metric_name = "ApproximateNumberOfMessagesVisible"
namespace = "AWS/SQS"
period = 60
statistic = "Sum"
threshold = var.trigger_messages_threshold
alarm_description = "SQS messages in the queue are above the threshold."
alarm_actions = [
aws_appautoscaling_policy.scale_out_scanner_based_on_queue_depth.arn,
]
dimensions = {
QueueName = aws_sqs_queue.files_to_scan.name
}
}
resource "aws_cloudwatch_metric_alarm" "uploads_queue_depth_below_threshold" {
alarm_name = "${local.name_prefix}-queue-depth-below-threshold"
comparison_operator = "LessThanThreshold"
evaluation_periods = 1
metric_name = "ApproximateNumberOfMessagesVisible"
namespace = "AWS/SQS"
period = 60
statistic = "Sum"
threshold = var.trigger_messages_threshold
alarm_description = "SQS messages in the queue are below the threshold."
alarm_actions = [
aws_appautoscaling_policy.scale_in_scanner_to_zero.arn,
]
dimensions = {
QueueName = aws_sqs_queue.files_to_scan.name
}
}Auto scaling Terraform configs
Scale in fixed percentage on each step
Scale larger fleet, instead of adding +1 task as configured in the main example
variable "max_scanners" {
description = "The maximum number of scanner instances to run in parallel."
type = number
default = 64
}
variable "scanner_threshold_scaling_factor" {
description = "The scaling factor for the number of scanner instances to run in parallel. The lower the scaling factor, the less queue depth is needed to trigger a new scanner instance."
type = number
default = 1.5
}
variable "step_percent_from_max_scanners" {
description = "The percentage of the maximum number of scanners to scale up or down on each step. The higher the percentage, the less steps are needed to reach the maximum number of scanners. Must be between 0 and 1."
type = number
default = 0.20
}
locals {
scanner_scale_out_steps = [
# Iterate over the percentage of the maximum number of scanners to scale up or down on each step.
# Second value in `range()` is exclusive, so we add a step percent value to the upper bound to include `1` in the range.
for index, percentage in range(var.step_percent_from_max_scanners, 1 + var.step_percent_from_max_scanners, var.step_percent_from_max_scanners) : {
step_index = index + 1
# The number of scanners to scale up or down on each step.
count = floor(var.max_scanners * percentage)
# Will always be 0 for the first step.
lower_bound = floor(index * var.trigger_messages_threshold * pow(var.scanner_scaling_factor, index))
# Should be `null` for the last step, because only the lower bound value is needed.
upper_bound = percentage == 1 ? null : floor((index + 1) * var.trigger_messages_threshold * pow(var.scanner_scaling_factor, index + 1))
}
]
}
resource "aws_appautoscaling_policy" "scale_out_scanner_based_on_queue_depth" {
name = "scale-out"
policy_type = "StepScaling"
resource_id = aws_appautoscaling_target.scanner_service.resource_id
scalable_dimension = aws_appautoscaling_target.scanner_service.scalable_dimension
service_namespace = aws_appautoscaling_target.scanner_service.service_namespace
step_scaling_policy_configuration {
adjustment_type = "ExactCapacity"
cooldown = 60
metric_aggregation_type = "Average"
dynamic "step_adjustment" {
for_each = local.scanner_scale_out_steps
iterator = step
content {
metric_interval_lower_bound = step.value.lower_bound
metric_interval_upper_bound = step.value.upper_bound
scaling_adjustment = step.value.count
}
}
}
}Output example:

Quirks I’ve encountered
Sometimes the desired count of 0 is set with a delay (11 min in one case with a cooldown of a policy equal to 1 min), and sometimes not (almost instantly).q Worth investigating if presents itself as a problem.
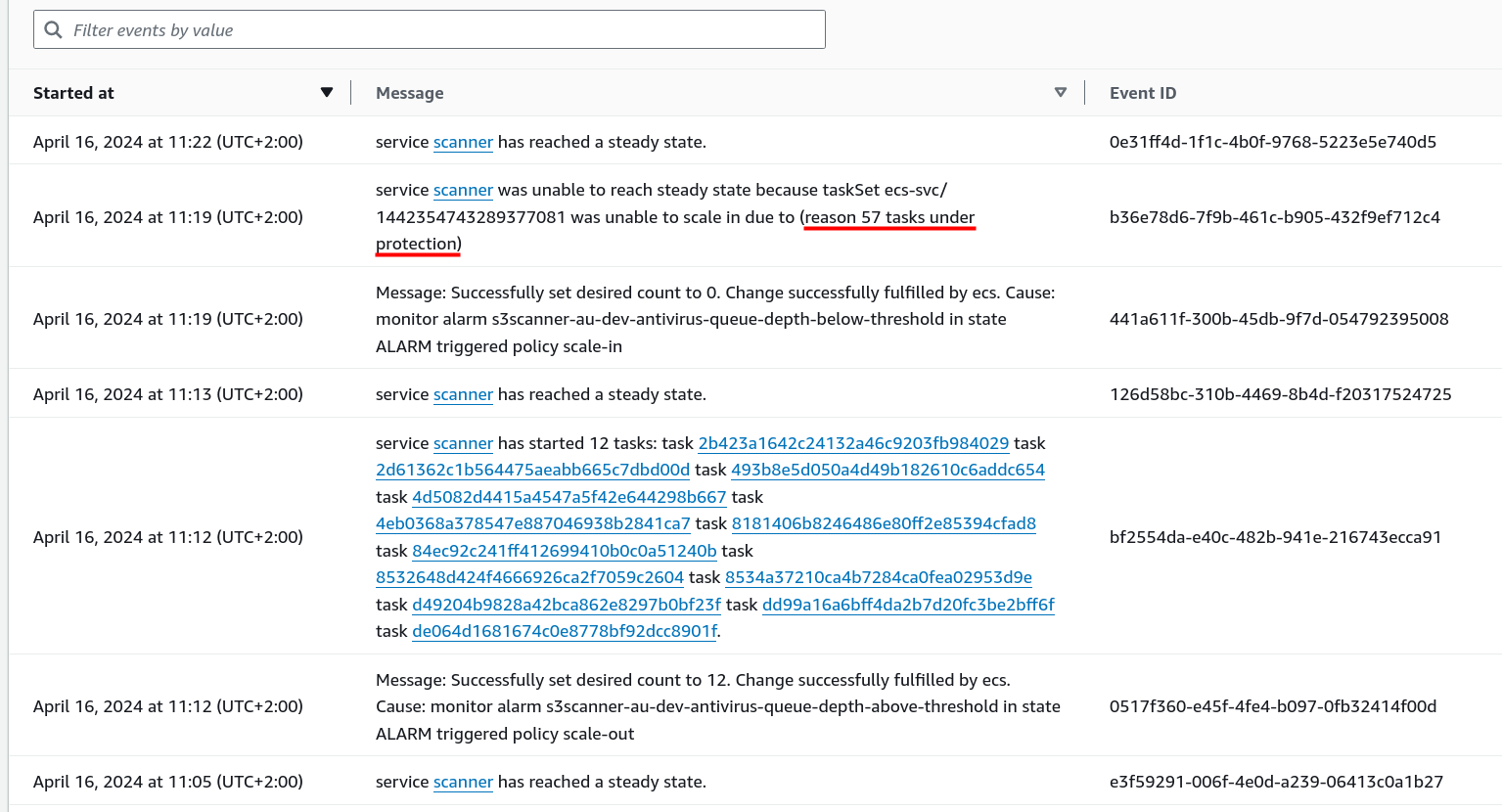
Task protection from scale-in events
This protection will allow to task to finish its work before it will be deprovisioned. This feature was released at the end of 2022.
By default any task may be interrupted by scale-in event and forced to deprovision. It may result in the interruption of the expensive computational processing of long-running tasks.
How task can protect itself from within the container
It needs to make a request to the ECS scale-in protection endpoint (endpoint docs).
PUT $ECS_AGENT_URI/task-protection/v1/state -d
'{"ProtectionEnabled":true}'
You can also set a "ExpiresInMinutes". Default value is 2 hours, for my purposes it was more than enough.
$ECS_AGENT_URI is a special environment variable that is set by ECS in the container.
Example in Python:
import requests
...
def enable_current_task_protection() -> None:
logger.info("Enabling protection for task")
requests.put(
f"{os.environ['ECS_AGENT_URI']}/task-protection/v1/state",
json={
"ProtectionEnabled": True,
"ExpiresInMinutes": os.environ.get("MAX_PROTECTION_MINUTES", 60 * 2),
},
)
logger.info("Protection enabled for task")These permissions should be attached to the role:
ecs:GetTaskProtectionecs:UpdateTaskProtection
How to protect task outside of the container
Use ECS API UpdateTaskProtection.
boto3 ecs.update_task_protection() docs.
How to disable task protection
def disable_current_task_protection() -> None:
logger.info("Disabling protection for task")
requests.put(
f"{os.environ['ECS_AGENT_URI']}/task-protection/v1/state",
json={
"ProtectionEnabled": False,
},
)
logger.info("Protection disabled for task")How to check if task is protected
With AWS CLI:
aws ecs get-task-protection --cluster arn:aws:ecs:<region>:<account_id>:cluster/<cluster_id> --tasks <task_id_or_arn>Example response when task is protected:
{
"protectedTasks": [
{
"taskArn": "arn:aws:ecs:<region>:<account_id>:task/<task_id>",
"protectionEnabled": true,
"expirationDate": "2024-04-13T18:14:19+02:00"
}
],
"failures": []
}
Example response when task is NOT protected:
{
"protectedTasks": [
{
"taskArn": "arn:aws:ecs:<region>:<account_id>:task/<task_id>",
"protectionEnabled": false
}
],
"failures": []
}
Disable task protection before leaving from the essential container
Completed and already closed tasks are counted as protected in ECS service and skews the numbers in logs.